Computational workflows like Shundlikht and Dybbukcan generate machine-actionable data from “raw” (e.g. handwritten and printed) sources, allowing the search of vast material collections, but while a keyword search is a useful way to collate and confirm hypotheses, it assumes the researcher has some ideas about where to begin; some existing research questions. So, how might one glimpse the contents of a text corpus, to generate preliminary research questions that might inform downstream search and more sophisticated analyses related to topics, sentiments, parts of speech, or named entities? One way is to engage with the full text of a work in virtual reality, using Longhand.
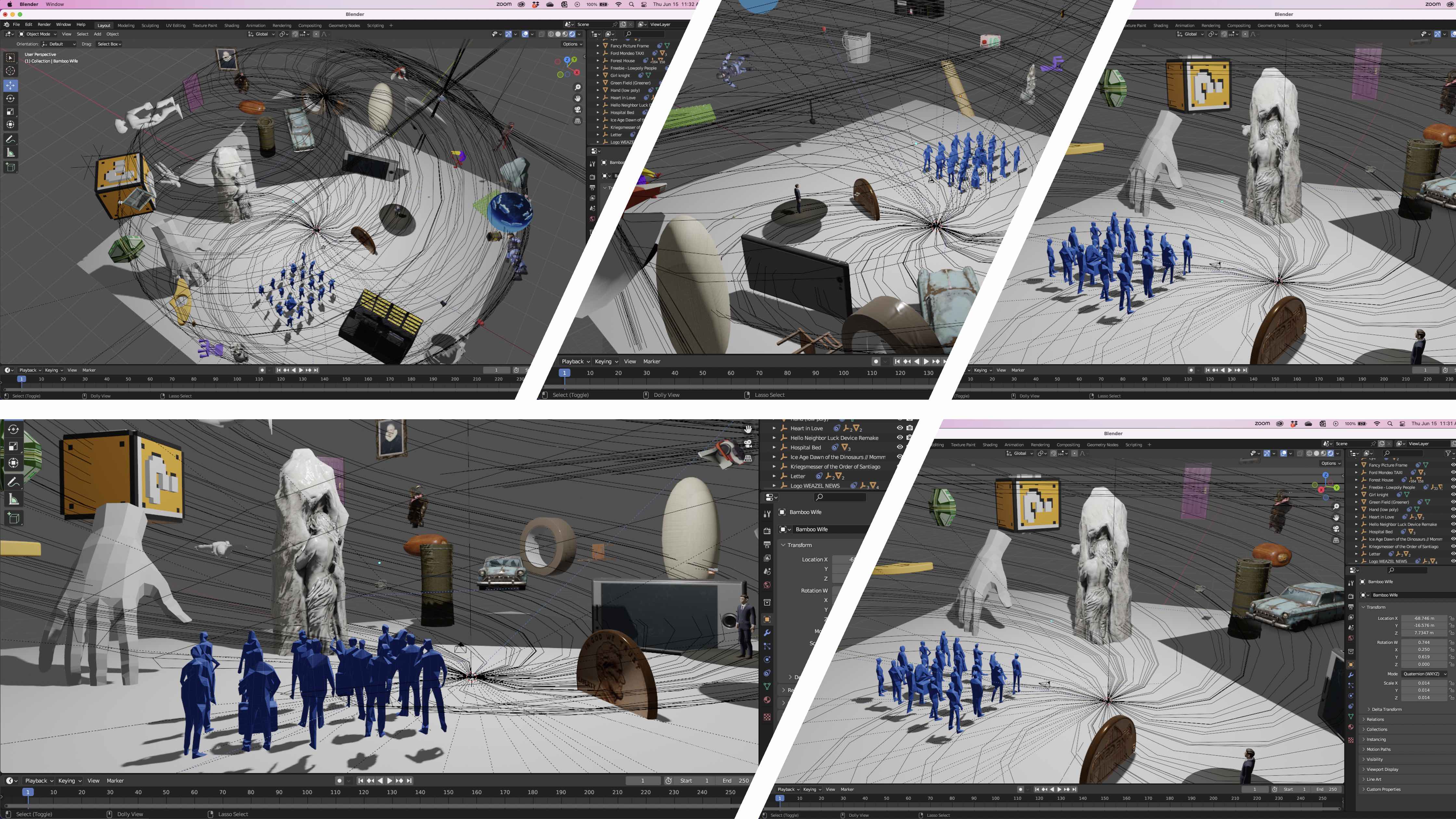
Longhand is a word cloud generator, but the words are 3D models projected 360 degrees. The individual models represent text tokens, identified by natural language processing (NLP) workflows, and realized in VR through a 3D-model-database (Sketchfab) query. Longhand exposes text-centric researchers to the specific benefits of immersive visualization by retaining depth cues and embodiment. Longhand is moreover capable of simultaneously representing an unprecedented portion of a text corpus because 3D objects are recognizable as instances of tokens from arbitrary viewing angles.
Aside from its reliance on physical correlates for textual references (i.e. nouns), Longhand is limited by the occurrence of well-labeled, existing 3D assets in a commercial database, Sketchfab. Future iterations of the Longhand software might benefit from the integration of text-to-3D AI (e.g. Stable Dreamfusion), which can be deployed to generate more precise 3D representations of text collections for virtual exploration by distributed teams of digital humanists. For now, Longhand represents a novel way to initially engage with the full text contents of the Shund.org corpora.
Presented here is a Longhand screenshot representing the first 16 installments of Vu iz Feni (1933) by Miriam Karpilove, after it was processed and translated by Shundlikht. One can immediately see the limits of this process, given the prominence of a “penny”—the translation tool clearly has misread the first name of the main character, Fanny, which when spelled in Yiddish appears almost identical to the one-cent coin.
False positives are a problem, but high-frequency tokens in the story (e.g. “car”, “phone”, “people”, etc.) are also recognizable, and quickly, from arbitrary viewing angles, amidst competing visual inputs, making Longhand a powerful tool to explorea sizeable corpus, like Shund. Moreover, future versions of Longhand can integrate custom stopwords lists, derived from character lists, to minimize the inclusion of nonsensible models in the scene.